
今天來聊聊關於「離線使用 AI 的功能」。雖然目前各大廠牌(如 ChatGPT、Gemini、Claude)都提供了一定的免費使用額度,但這些額度通常很快就會被消耗完,無法應付長期需求。
針對這個問題,雖然我的筆電不符合AI PC NPU 效能標準(至少 40 TOPS),但利用更輕量的 AI 模型,例如 llama 3.2 - 3b 小語言模型,依然能在我的筆電上運行,提供一些離線測試的能力。
接下來,我將一步步介紹如何在 Windows 11 環境中安裝這些工具,讓我們一起完成這個過程吧!
筆者的設備為 Lenovo X1 Carbon,是一台輕便型的商務筆電,GPU 性能較為有限,因此選擇了相對輕量的模型來執行。
在開始安裝之前,我們需要先準備以下工具:
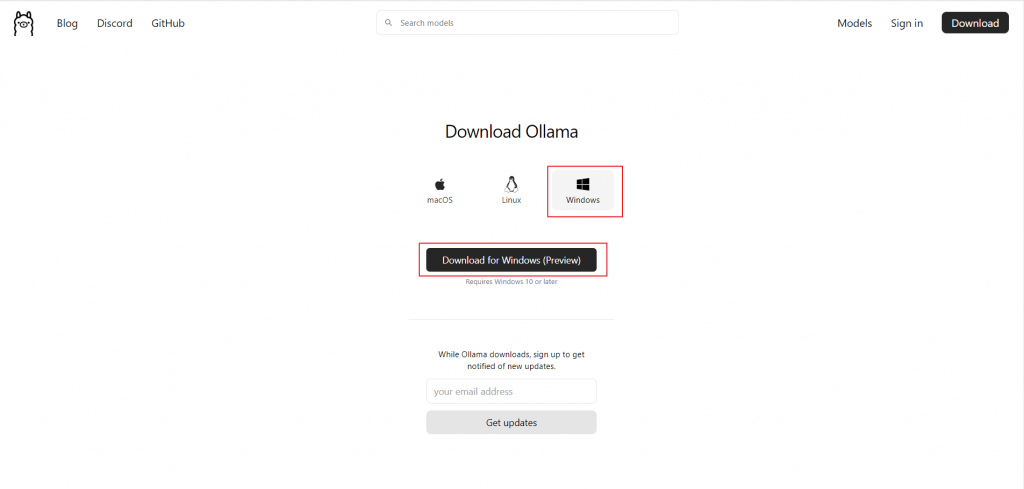
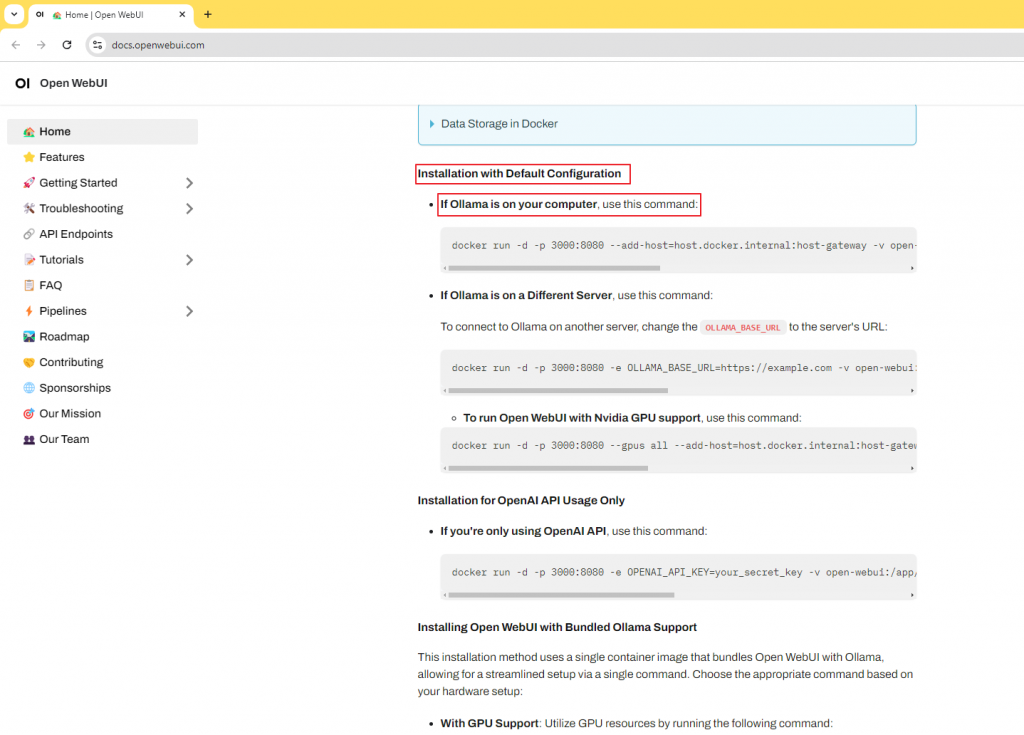
開啟Terminal 執行安裝 Open-WebUI
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always [ghcr.io/open-webui/open-webui:main](http://ghcr.io/open-webui/open-webui:main)
這邊提醒一下 3000 是我們本地使用的port 我們可以自己更換,不要跟原有的服務衝突
筆者這邊是使用 4000:8080
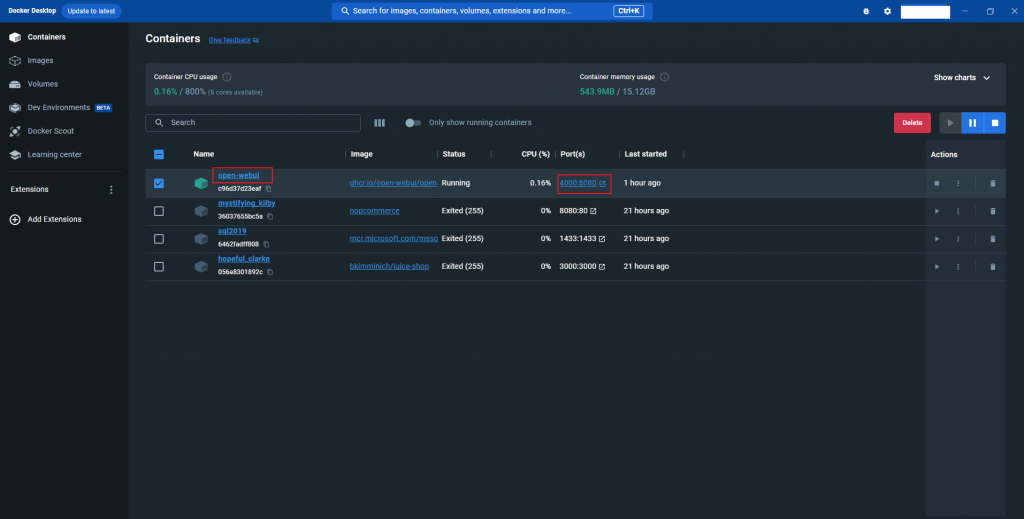
open-webui 成功在docker 執行
(第一次登入,要先建立帳號) 這個帳號資訊 只會落在本機
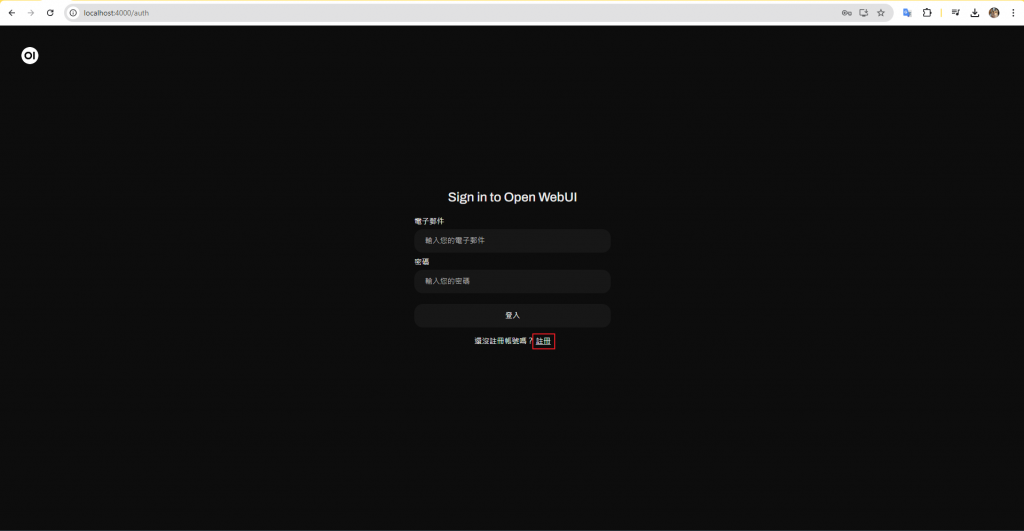
Open WebUI 不會建立任何外部連線,而且您的資料會安全地儲存在您本機伺服器上
登入成功
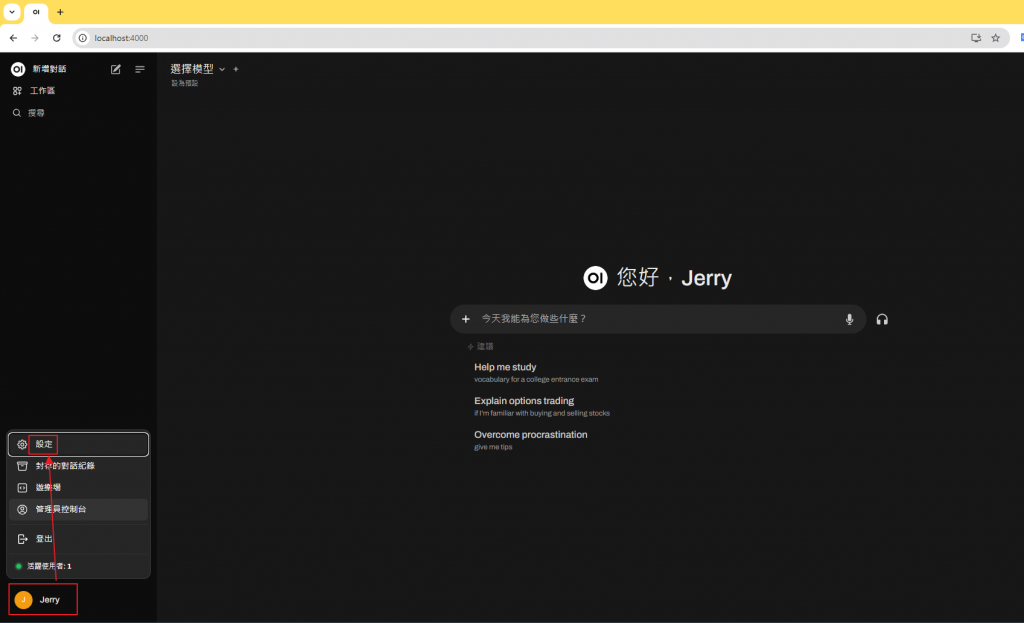
我們登入之後的第一件事情就是要先安裝我們的模型
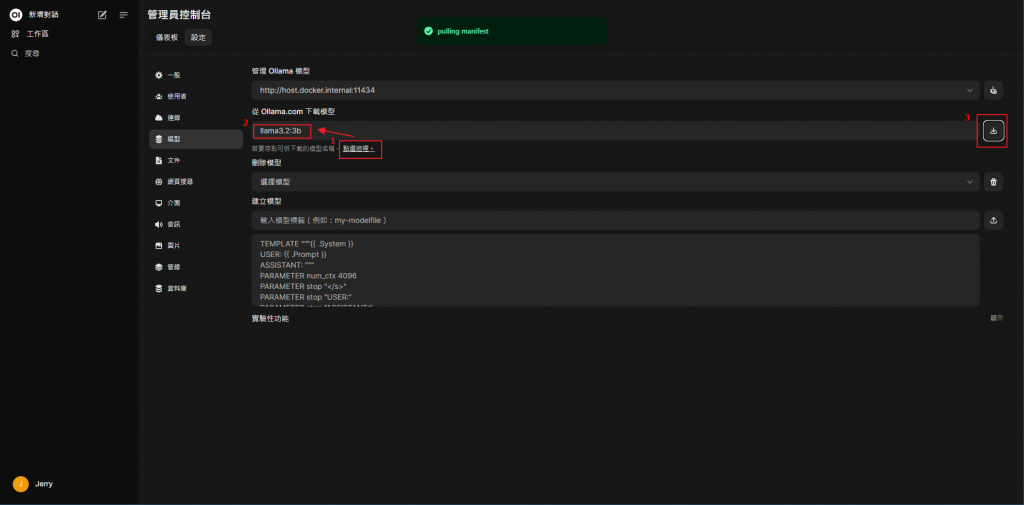
下載中
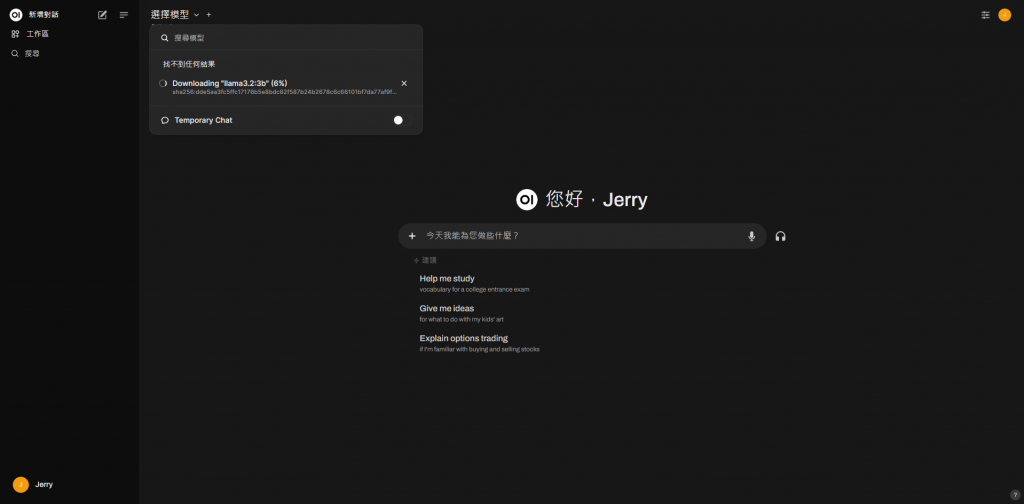
下載完成後 我們選取下載好的llama3.2
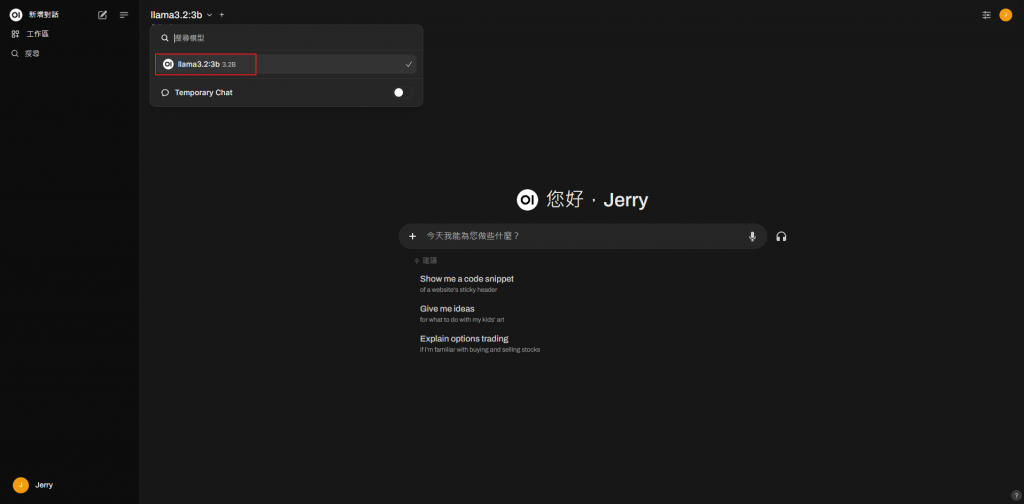
若有多個模型下載,也可以指定預設要使用的模型
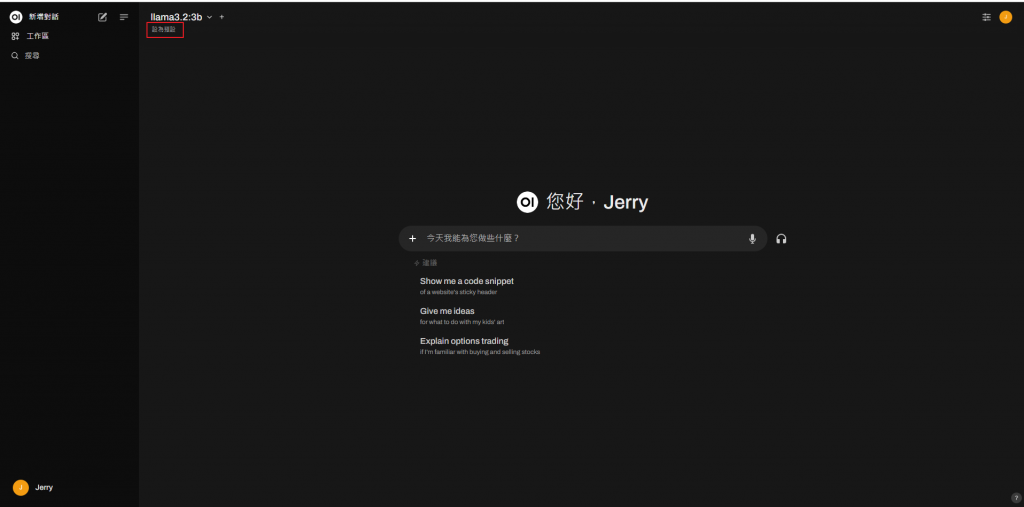
最大的好處就是 離線也能運作 (雖然中文支持程度沒有很好)
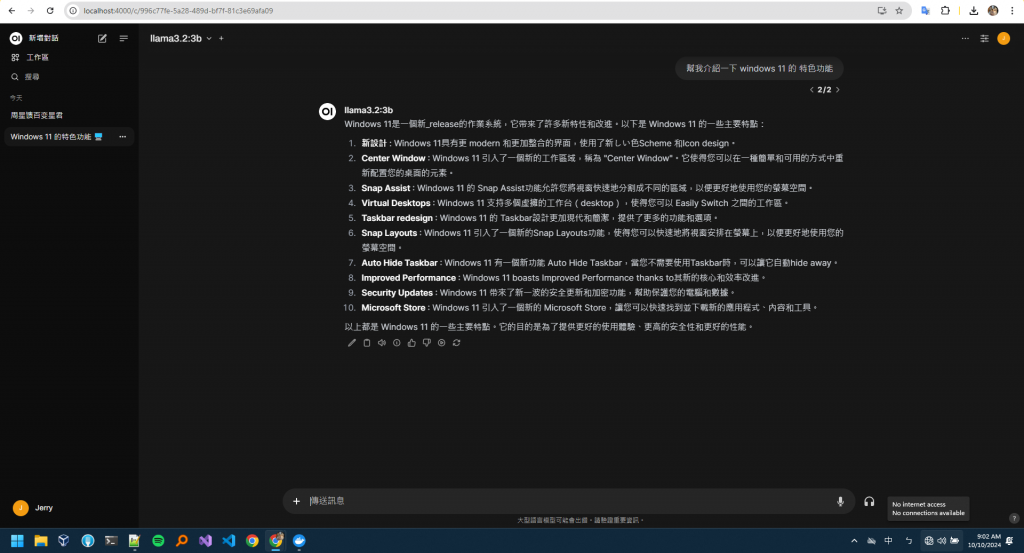
筆者目前使用的 X1 Carbon(2021 年)雖然符合升級至 Windows 11 的最低門檻,但在執行 AI 模型時,受到硬體限制,效能表現並不理想。未來若能升級配備 NPU、GPU 的設備,這些裝置將可能解鎖更多有趣的應用場景。
無論如何,離線使用 AI 模型的嘗試讓我們看到了更多的可能性,也希望未來有更多模型能夠在本地環境中流暢運行。
